From Prototype to Production: How to Deploy AI Agents That Actually Work
Every data scientist knows the frustration—your brilliant AI agent works perfectly in the notebook, then fails spectacularly in production. The gap between prototype and production-ready AI is where most projects die. Here's how to cross that chasm with confidence.
The Prototype vs. Production Reality Gap
Creating an AI agent prototype has never been easier—frameworks like CrewAI and LangGraph let you spin up functional agents in just four steps: define tools, select an LLM, craft system prompts, and integrate components. But as the video explains at 1:15, "This is where the hero's journey really begins."
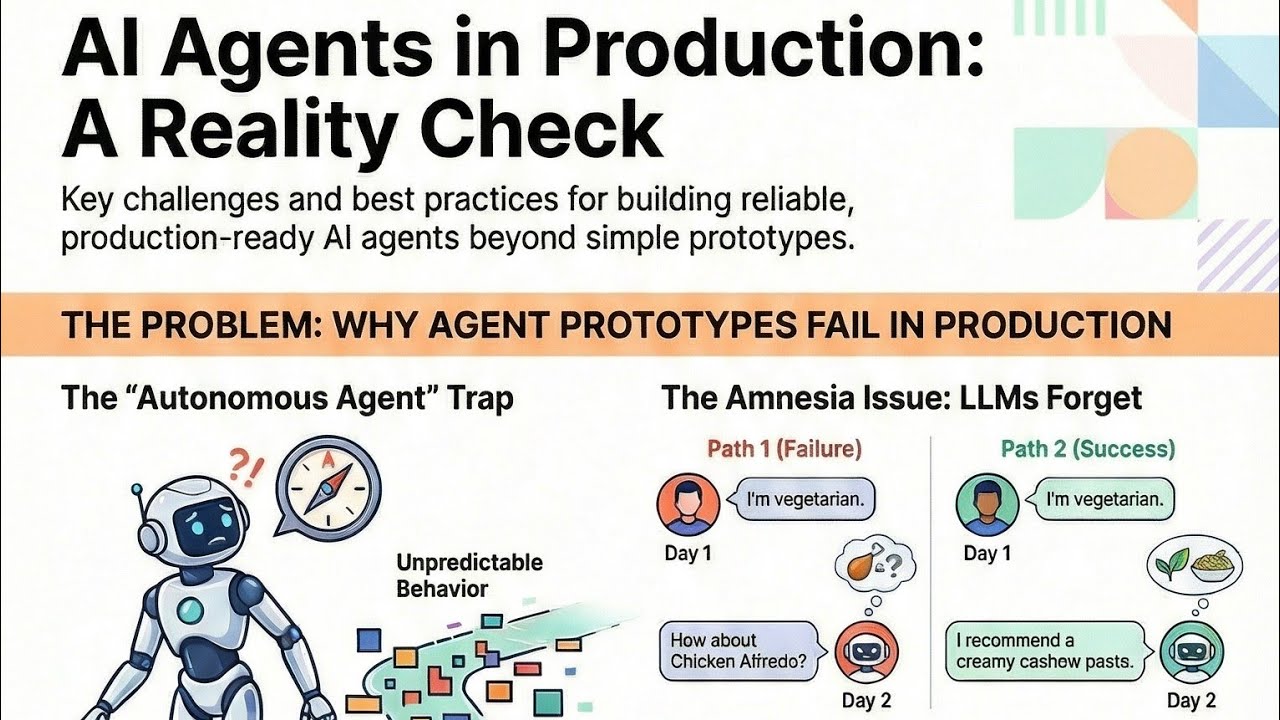
The notebook environment is a controlled sandbox—production is the wild west. Real users generate unpredictable inputs, systems have uptime requirements, and errors have business consequences. What worked beautifully in isolation often fails under real-world conditions.
80% of AI projects never make it to production, according to Gartner research. The majority fail not because of poor models, but due to inadequate productionization strategies.
4 Fundamental Production Challenges
When your agent leaves the lab, you'll face four core challenges that demand a systems engineering approach:
- Non-determinism: Same input → different outputs (at 2:30 in the video)
- Cascading failures: Small errors that compound dramatically
- Observability gaps: Black-box decision making
- Scaling fragility: Performance degradation under load
Traditional software engineering assumes determinism—if X then Y. AI agents break this fundamental premise. As highlighted at 3:10, "An agent's decision-making process can feel like a total black box." This requires new approaches to testing, monitoring, and error handling.
The Essential Production Toolkit
To overcome these challenges, you'll need three key tools (demonstrated at 4:20 in the video):
FastAPI: Creates a stable API interface so other systems can reliably call your agent
FastAPI wraps your Python agent in REST endpoints with proper input validation and error handling. This transforms your experimental code into a production-grade service.
Docker: Packages your agent with all dependencies into a portable container
Docker solves the "works on my machine" problem by creating identical environments across development, testing, and production. The video shows this packaging process at 5:45.
Evaluation Frameworks: Specialized testing for non-deterministic systems
Traditional unit tests fail with AI. Evaluation frameworks test whether outputs meet criteria rather than matching exact expectations.
Testing Strategies for Unpredictable AI
At 6:30, the video emphasizes: "Don't use mock data—it's too clean." Real-world testing requires:
- Scenario-based testing: Define what success looks like for key use cases
- Live environment testing: Expose agents to real-world variability
- Continuous evaluation: Monitor performance metrics over time
The analogy at 7:15 is perfect—just as unit tests verify code components, evaluations verify agent capabilities. This brings reliability to inherently unpredictable systems.
Critical testing practices include:
- Testing with production-like data volumes
- Validating error handling under failure conditions
- Measuring latency at expected load levels
Choosing Your Deployment Path
The video outlines four primary deployment options at 8:40:
| Option | Best For | Complexity |
|---|---|---|
| CrewAI CLI | Quick testing | Low |
| Git-based workflow | Team collaboration | Medium |
| API integration | Mature systems | High |
| Custom AWS | Maximum control | Very High |
Your choice depends on team size, scalability needs, and operational maturity. Simpler isn't always better—complex systems often require the control of custom deployments.
AWS Bedrock Deployment Example
At 9:50, the video demonstrates AWS Bedrock's clever versioning system:
- Versions: Immutable snapshots of your agent
- Aliases: Pointers to specific versions
This enables safe deployments with instant rollback capability—critical for production systems. If a new version fails, simply redirect the alias to the previous version.
Key Benefit: Zero-downtime updates with built-in safety nets
The deployment process:
- Package agent in Docker container
- Upload as new Bedrock version
- Test thoroughly in staging
- Update production alias when verified
Watch the Full Tutorial
See the complete walkthrough of packaging an AI agent with FastAPI and Docker (starting at 4:20 in the video), including live demonstrations of the version/alias deployment system in AWS Bedrock.
Key Takeaways
Transitioning AI agents from prototype to production requires fundamental shifts in approach:
In summary: Treat your agent as a production system first, AI model second. Implement API interfaces, containerization, and specialized testing. Choose deployment architecture based on your scalability needs and operational maturity.
The real work begins after the prototype—but with the right tools and mindset, you can deploy AI agents that deliver real business value.
Frequently Asked Questions
Common questions about AI agent deployment
The four fundamental challenges are non-determinism (different answers to same input), cascading failures (small errors leading to major deviations), observability gaps (difficulty tracking decision paths), and scaling fragility (performance degradation under load).
These require shifting from a model-building to systems-engineering mindset. Where traditional software expects deterministic outputs, AI agents introduce probabilistic behavior that demands new approaches to reliability.
- Non-determinism breaks traditional testing approaches
- Cascading errors can quickly derail agent workflows
- Black-box decisions complicate debugging
Three key tools solve the core production challenges: FastAPI for creating stable interfaces, Docker for environment consistency, and evaluation frameworks for testing unpredictable behavior.
Together these address the reliability gaps between prototype and production. FastAPI provides API stability, Docker ensures environment consistency, and evaluation frameworks validate behavior under real-world conditions.
- FastAPI transforms Python code into production-grade services
- Docker containers guarantee environment parity
- Evaluation frameworks replace traditional unit testing
Instead of exact-match testing, use evaluation frameworks that define success criteria for scenarios. Focus on whether outputs meet requirements rather than matching specific expected values.
Testing must occur with real-world data in live environments—mock data is too clean and won't reveal production issues. The most effective strategy combines scenario testing, live environment exposure, and continuous performance monitoring.
- Test capabilities rather than exact outputs
- Use production-like data volumes and variety
- Monitor performance metrics over time
Four primary paths exist: specialized platforms (Crew AI AMP) for simplicity, cloud services (AWS/GCP) for control, serverless options (Vercel) for lightweight needs, or custom infrastructure for complex requirements.
The choice depends on your team's scale, technical maturity, and reliability needs. AWS Bedrock's version/alias system provides particularly robust deployment capabilities with safe rollback features.
- Specialized platforms offer streamlined workflows
- Cloud services provide maximum flexibility
- Serverless works well for simple applications
Docker containers package the agent with all its dependencies into a standardized unit that runs identically across environments. This eliminates environment-specific issues that plague AI deployments.
By containerizing your agent, you ensure the same behavior whether running on a developer's laptop, CI/CD pipeline, or production cluster. This environmental consistency is critical for reliable operation.
- Eliminates "works on my machine" problems
- Standardizes dependencies across environments
- Simplifies deployment to various platforms
Implement comprehensive logging of decision paths, API call tracking, and performance metrics. Use specialized LLM observability tools that can handle non-deterministic outputs while providing actionable insights.
Effective monitoring requires establishing baseline behavior metrics to detect degradation. Focus on tracking both technical performance (latency, error rates) and business outcomes (task completion rates, quality scores).
- Log decision paths for traceability
- Track API call performance and errors
- Monitor both technical and business metrics
Underestimating the systems engineering requirements. Teams often focus solely on model performance while neglecting API stability, error handling, and monitoring infrastructure.
The prototype mindset assumes "if the AI works, deployment will be easy." In reality, productionizing AI requires treating the agent as a mission-critical system with all the accompanying reliability, monitoring, and maintenance requirements.
- Focusing only on model accuracy
- Neglecting API design and error handling
- Underinvesting in monitoring solutions
GrowwStacks specializes in bridging the gap between AI prototypes and production systems. We design deployment architectures, implement testing frameworks, and build monitoring solutions tailored to your agents.
Our team handles the complex engineering challenges of productionization—containerization, API design, error handling, and observability—so you can focus on the AI innovation. We've deployed over 200 AI workflows across industries with 99.9% reliability.
- Custom deployment architectures for your specific needs
- Implementation of robust testing frameworks
- Comprehensive monitoring and alerting systems
- Free 30-minute consultation to assess your requirements
Ready to Deploy Your AI Agent with Confidence?
Every day your AI stays in prototype is a day it's not delivering business value. GrowwStacks specializes in transforming promising prototypes into production-grade AI systems—reliable, scalable, and measurable.