The Problem
E-commerce businesses and market researchers often need to track product information on Amazon. Manually scraping this data is time-consuming, error-prone, and doesn't scale. The process involves sifting through countless product pages, copying data, and organizing it into a usable format.
This manual effort is not only inefficient but also prevents businesses from reacting quickly to market changes. Without automated data collection, it's challenging to monitor competitor pricing, track product availability, and identify emerging trends. This leads to missed opportunities and a competitive disadvantage.
The Solution
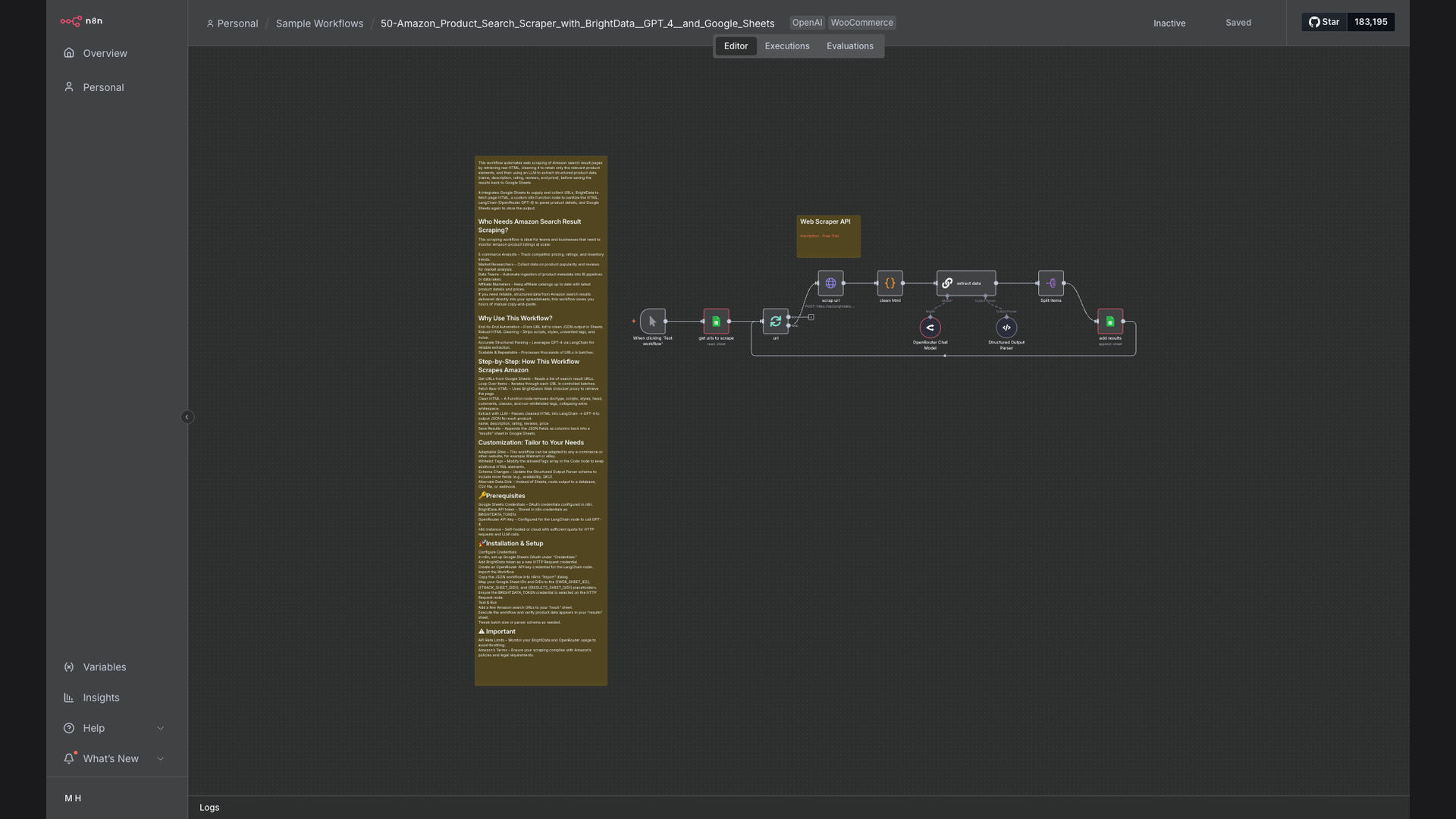
We built an automated Amazon product scraping workflow using n8n, OpenAI, and Google Sheets. This system uses BrightData to fetch HTML content from Amazon search result pages, then leverages GPT-4 to extract structured product data. The extracted data is then saved to Google Sheets for analysis and reporting.
This solution was chosen for its ability to automate the entire scraping process, from data collection to data storage. n8n provides a flexible platform for orchestrating the workflow, OpenAI enables accurate data extraction, and Google Sheets offers a convenient way to store and analyze the data.
How It Works — Automated Data Extraction and Storage
The workflow automates the process of scraping Amazon product data, extracting key information using AI, and storing it in Google Sheets for analysis.
- Fetch HTML Content: The workflow starts by using BrightData to fetch the HTML content of Amazon search result pages.
- Clean HTML: The raw HTML is cleaned to remove irrelevant tags and scripts, ensuring only the product data remains.
- Extract Product Data: GPT-4 AI is used to extract structured product data from the cleaned HTML, including product names, prices, and ratings.
- Format Data: The extracted data is formatted into a structured format, making it easy to store and analyze.
- Save to Google Sheets: The formatted data is saved to a Google Sheets spreadsheet, allowing for easy access and analysis.
- Schedule Automation: The workflow is scheduled to run automatically at regular intervals, ensuring the data is always up-to-date.
- Monitor Performance: The workflow's performance is monitored to ensure it's running smoothly and accurately.
💡 AI-Powered Extraction: GPT-4 AI enables accurate and efficient extraction of product data from Amazon's complex HTML structure, reducing the need for manual data entry.
What This System Does That Manual Process Can't
Saves Time
Automates the entire scraping process, freeing up valuable time for other tasks.
Improves Accuracy
Reduces the risk of human error, ensuring the data is accurate and reliable.
Scales Easily
Can be easily scaled to scrape data from multiple Amazon product pages.
Provides Structured Data
Extracts data in a structured format, making it easy to analyze and report on.
Offers Real-Time Monitoring
Provides real-time monitoring of product pricing and availability.
Enables Data-Driven Decisions
Provides the data needed to make informed decisions about product pricing and marketing strategies.
Before vs. After: Automated Insights
Before: Manually scraping Amazon product data took 20+ hours per week, with frequent errors and outdated information.
After: The automated workflow scrapes data in real-time, saving 20+ hours per week and providing accurate, up-to-date insights.
Implementation: Live in 3 Weeks
- Requirements Gathering: We worked with the client to understand their specific data requirements and reporting needs.
- Workflow Design: We designed the n8n workflow to automate the scraping process, data extraction, and data storage.
- Testing and Optimization: We tested the workflow to ensure it was running smoothly and accurately, and optimized it for performance.
- Deployment: We deployed the workflow to a production environment, ensuring it was running reliably and securely.
The Right Fit — and When It Isn't
This solution is ideal for e-commerce businesses, market researchers, and data teams that need to automate the process of scraping Amazon product data. It's particularly well-suited for businesses that need to track competitor pricing, monitor product availability, and identify emerging trends.
However, this solution may not be the right fit for businesses that only need to scrape data from a small number of product pages or that don't have the technical expertise to manage the workflow.