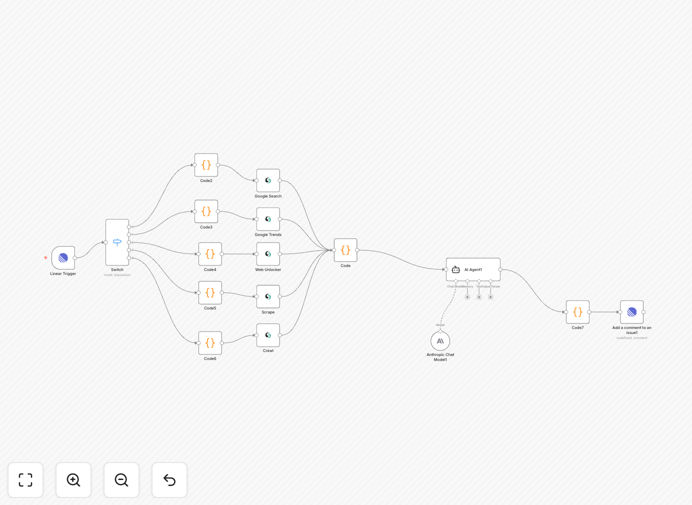
What This Workflow Does
This AI-powered research assistant transforms how teams gather and process information by combining Linear's issue tracking with Scrapeless's web data extraction and Claude AI's natural language processing. It allows team members to submit research requests in plain English through Linear, which then triggers automated data collection, analysis, and structured reporting.
The system eliminates hours of manual research work by automatically processing complex queries like "Find the top 5 competitors in our space with funding rounds in the last year" or "Summarize recent product updates from these three websites." Results are delivered back to Linear as formatted comments or attachments, creating a seamless research workflow within your existing project management tool.
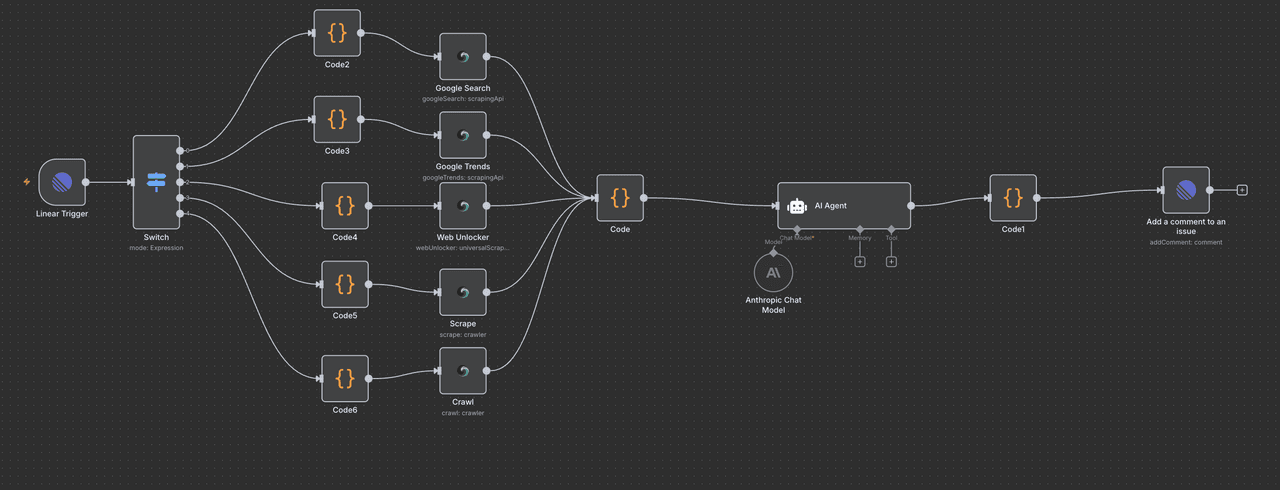
How It Works
1. Research request submission
Team members create a new issue in Linear with a specific label (like "Research") and describe their request in natural language. The workflow monitors Linear for new issues with this label.
2. AI task interpretation
Claude AI analyzes the request to determine required data sources, extraction methods, and output format. It breaks down complex queries into actionable steps and identifies any ambiguities needing clarification.
Pro tip: Structure requests with clear objectives like "Compare features X, Y, Z between Product A and Product B" for best results.
3. Automated data collection
Scrapeless extracts relevant information from specified web sources, handling JavaScript-rendered content and bypassing anti-scraping measures. The system gathers data from multiple pages or APIs as needed.
4. AI analysis and synthesis
Claude processes the raw data, identifying key patterns, comparisons, and insights. It generates human-readable summaries, tables, or reports based on the original request's requirements.
5. Results delivery
The formatted research findings are posted back to the original Linear issue as a comment or attachment, closing the automation loop. Team members receive notifications when their research is complete.

Who This Is For
This workflow benefits product teams, market researchers, competitive intelligence specialists, and anyone who regularly conducts web-based research. It's particularly valuable for:
- Startup founders tracking competitor movements
- Product managers conducting feature comparisons
- Marketing teams monitoring industry trends
- Investment analysts researching company landscapes
- Consultants preparing client deliverables
What You'll Need
- An n8n instance (self-hosted or cloud)
- Linear account with API access
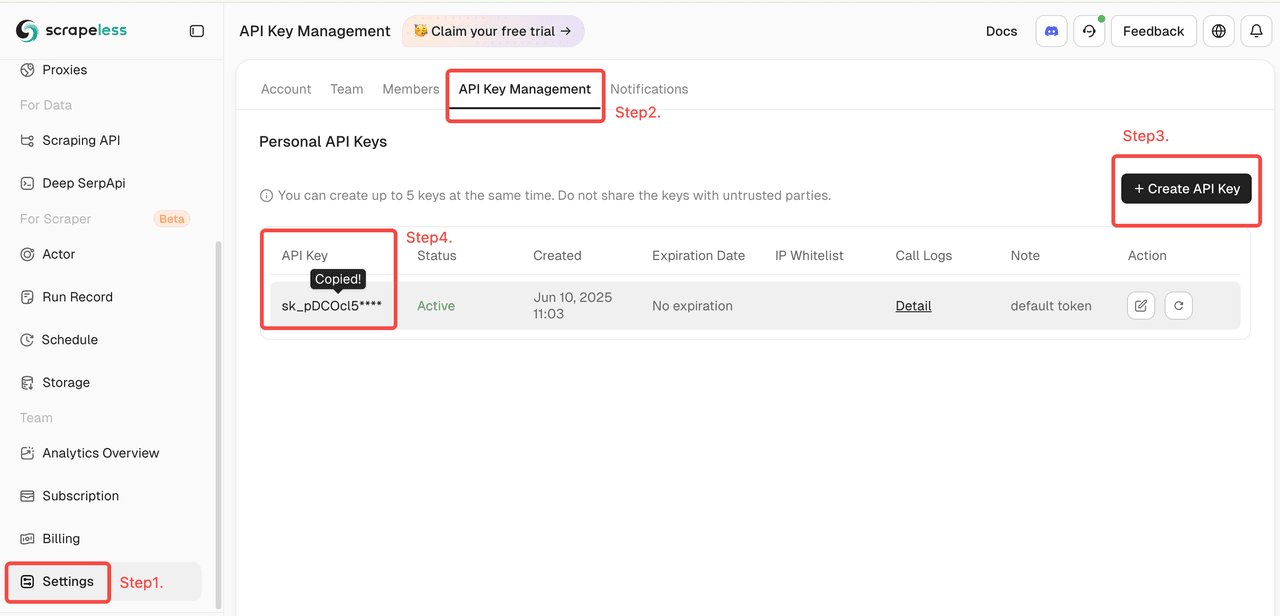
- Scrapeless API credentials
- Claude AI API access
- Webhook configuration permissions
Quick Setup Guide
- Download and import the JSON template into your n8n instance
- Configure API connections for Linear, Scrapeless, and Claude
- Set up a webhook in Linear to trigger on new research-labeled issues
- Test with simple research requests before complex queries
- Adjust output formatting to match your team's preferences
Key Benefits
Reduce research time by 70-90%: What previously took hours of manual searching and analysis now happens automatically in minutes.
Improve research consistency: Eliminate human variability in data collection and reporting with standardized automated processes.
Scale research capacity: Handle multiple concurrent research requests without adding staff or overtime.
Enhance decision velocity: Get critical business intelligence faster, accelerating product and strategy decisions.
Centralize research tracking: Maintain all research artifacts and history directly in Linear alongside related projects.