What This Workflow Does
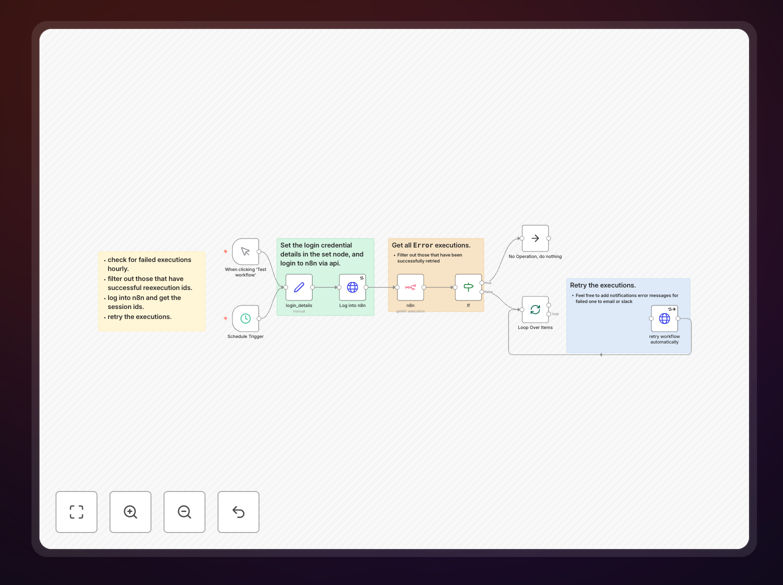
The Auto-Retry Engine workflow automatically recovers from temporary failures in your automated processes. When API calls, database operations, or other tasks fail due to network issues, rate limits, or temporary service interruptions, this workflow intelligently retries the operation with configurable delays rather than failing completely.
Businesses lose countless hours manually restarting failed workflows or troubleshooting temporary glitches. This solution eliminates that wasted effort by implementing professional-grade error handling that would normally require custom coding. The workflow includes notification systems to alert teams only when persistent failures occur.
How It Works
1. Error detection and classification
The workflow monitors operations for specific error codes or patterns that indicate temporary failures. It distinguishes between retryable errors (like network timeouts) and permanent failures (like invalid credentials) that require different handling.
2. Smart retry scheduling
Using exponential backoff algorithms, the workflow waits progressively longer between retry attempts. This prevents overwhelming recovering systems while maximizing success chances. You can configure maximum retry counts and delay intervals.
3. Success monitoring
After each successful retry, the workflow continues normal processing. Success metrics are logged for performance monitoring and optimization of retry parameters.
4. Failure escalation
If all retries fail, the workflow triggers notifications via email, Slack, or other channels. This ensures human intervention only when truly needed while keeping stakeholders informed.
Pro tip: Combine this with workflow pause/resume functionality to handle longer outages without losing progress.
Who This Is For
This workflow benefits any business running automated processes that interact with external systems. It's particularly valuable for:
- E-commerce stores processing orders through multiple APIs
- SaaS companies syncing data between platforms
- Marketing teams running multi-step automation sequences
- IT departments managing system integrations
What You'll Need
- An n8n instance (self-hosted or cloud)
- Basic understanding of your workflow's error patterns
- Notification channel setup (email/Slack/webhook)
- Permissions to modify existing workflows
Quick Setup Guide
- Download the JSON template file
- Import into your n8n instance
- Configure your error detection criteria
- Set retry limits and delay intervals
- Connect your notification channels
- Test with simulated failures
- Deploy to production workflows
Key Benefits
Reduce manual troubleshooting by 80%: Automatic recovery handles most temporary failures without human intervention.
Improve workflow success rates: Smart retry logic converts would-be failures into successful completions.
Get alerted only when needed: Notifications fire only after exhaustive retries, reducing alert fatigue.
Configurable for any use case: Adjust retry counts, delays, and notifications to match your specific requirements.