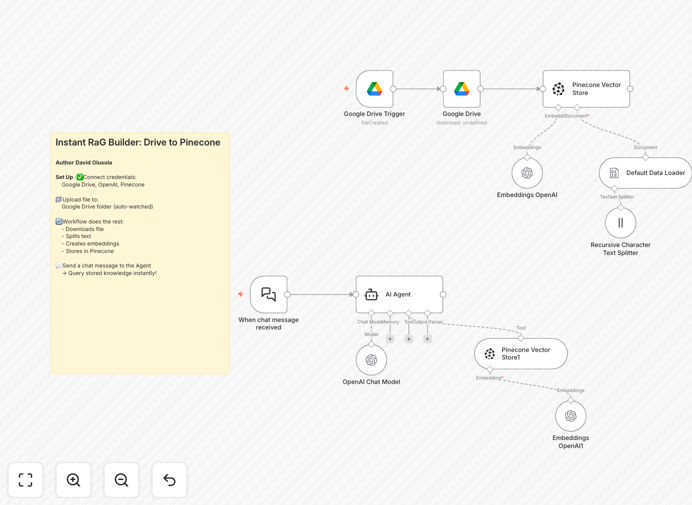
What This Workflow Does
This RAG (Retrieval-Augmented Generation) Pipeline automates the entire process of turning your Google Drive documents into an AI-ready knowledge base. It detects new files, processes their content, and makes them searchable through natural language queries.
The system combines the strengths of Google Drive for document storage, OpenAI for understanding content, and Pinecone for efficient retrieval. The LangChain integration manages the conversation flow, ensuring responses are grounded in your actual documents rather than generic AI knowledge.
How It Works
1. Document Ingestion
The workflow monitors a specified Google Drive folder for new files. When detected, it downloads the document and prepares it for processing.
2. Text Processing
Documents are split into logical chunks using a recursive text splitter. This maintains context while creating manageable pieces for the AI to process.
3. Vectorization
OpenAI's embedding model converts each text chunk into a numerical vector that captures its semantic meaning. These vectors enable similarity-based searches.
4. Vector Storage
Processed vectors are stored in Pinecone's specialized vector database, organized for fast retrieval based on semantic similarity.
5. Query Handling
When users ask questions, the system retrieves the most relevant document chunks from Pinecone and uses GPT-4o-mini to generate contextual answers.
Who This Is For
This workflow is ideal for:
- Teams maintaining internal knowledge bases
- Customer support departments needing quick access to documentation
- Researchers managing large collections of reference materials
- Companies wanting to make their documentation more accessible
- Developers prototyping AI-powered search solutions
What You'll Need
- Google Drive account with documents to process
- OpenAI API key (GPT-4o-mini access)
- Pinecone account and API credentials
- n8n instance (self-hosted or cloud)
- Basic understanding of API authentication
Quick Setup Guide
- Download the JSON template file
- Import into your n8n instance
- Configure credentials for Google Drive, OpenAI, and Pinecone
- Set your target Google Drive folder path
- Adjust chunking parameters for your document types
- Deploy the workflow and test with sample queries
Key Benefits
Automated knowledge management: Transform static documents into an always-updated, searchable knowledge base without manual intervention.
Context-aware responses: Get answers grounded in your specific documents rather than generic AI knowledge, reducing hallucinations.
Scalable architecture: The modular design handles everything from small document collections to enterprise-scale knowledge bases.
Natural language interface: Team members can ask questions in plain English without learning complex search syntax.
Continuous learning: As you add more documents, the system automatically incorporates them into its knowledge base.