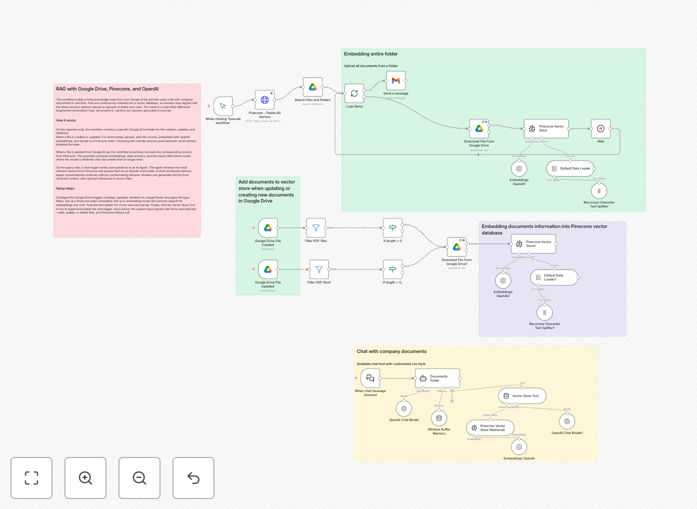
What This Workflow Does
This automation solves the problem of scattered, unsearchable company knowledge. Teams waste hours digging through Google Drive folders, emails, and shared documents to find specific information. This workflow creates a self-updating AI knowledge base that understands your content and provides instant, accurate answers.
It implements a complete Retrieval-Augmented Generation (RAG) pipeline that automatically syncs your Google Drive documents to a Pinecone vector database. When documents are added, updated, or deleted, the system processes those changes in real-time. Then, through a chat interface, you can ask natural language questions and get responses grounded exclusively in your company's documentation.
How It Works
1. Document Monitoring & Sync
The workflow watches a specified Google Drive folder for changes. When a file is created or modified, it downloads the content, splits it into manageable chunks using a recursive text splitter, and generates embeddings via OpenAI.
2. Vector Storage & Management
These embeddings (numerical representations of text meaning) are stored in Pinecone with metadata linking them to the source document. If a file is deleted from Drive, the corresponding vectors are automatically removed from Pinecone, maintaining a clean index.
3. Intelligent Query & Response
When a user asks a question through the chat interface, the system searches Pinecone for the most relevant document chunks, injects that context into a prompt, and uses OpenAI's chat model to generate a coherent, sourced answer.
Pro tip: Start with a dedicated "knowledge base" folder in Google Drive. This keeps the automation focused on verified company documents rather than personal or temporary files.
Who This Is For
This template is ideal for teams that rely heavily on documentation: product teams with technical specs, HR departments with policy manuals, consulting firms with client reports, legal teams with contract libraries, and support teams with solution databases. It's particularly valuable for remote teams who need instant access to institutional knowledge without bothering colleagues.
What You'll Need
- A Google Cloud Project with the Drive API enabled and service account credentials.
- An OpenAI API key with access to embeddings and chat models.
- A Pinecone account with an index created for vector storage.
- An n8n instance (cloud or self-hosted) to run the workflow.
- A dedicated Google Drive folder containing the documents you want to make searchable.
Quick Setup Guide
- Import the template: Download the JSON file and import it into your n8n instance.
- Configure credentials: Set up the Google Drive, OpenAI, and Pinecone credentials in n8n's credentials management.
- Set your folder ID: Update the Google Drive trigger node with the ID of the folder you want to monitor.
- Test the sync: Add a test document to your Drive folder and trigger the workflow to verify embedding generation and Pinecone storage.
- Ask questions: Use the chat trigger node or connect the workflow to a webhook/interface to start querying your documents.
Key Benefits
Instant knowledge access reduces employee search time by 80%. Instead of manually browsing folders or using basic keyword search, team members get precise answers in seconds, dramatically improving productivity.
Always-current information eliminates outdated guidance. The automatic sync ensures answers reflect the latest document versions, preventing decisions based on obsolete policies or specifications.
Scalable beyond human capacity. The system can index thousands of documents and retrieve relevant information across all of them simultaneously—something impossible for humans to do manually.
Controlled, private AI without data sharing. Unlike public chatbots, your company data stays within your ecosystem (Drive, your OpenAI account, your Pinecone index), maintaining security and compliance.
Reduces repetitive question overhead. Common questions about policies, procedures, or project details are answered automatically, freeing experienced staff for higher-value work.