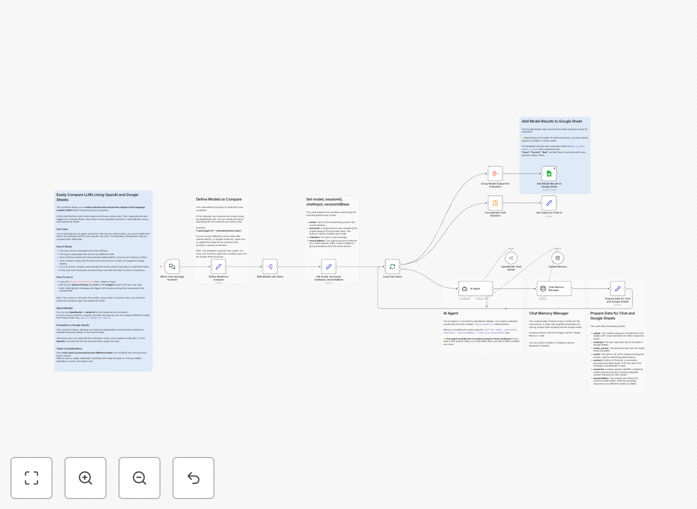
What This Workflow Does
Choosing the right language model (LLM) for your AI application is critical. Different models produce varied outputs—some are more creative, others more factual, some faster, others cheaper. Manual comparison is tedious and inconsistent.
This n8n workflow automates the comparison process. It sends the same user prompt to two different LLMs simultaneously, captures their responses, logs everything into a Google Sheet for review, and displays both answers side-by-side in a chat interface. You get a structured, repeatable way to evaluate which model performs best for your specific use case before committing to production.
Whether you're building a chatbot, an AI agent, or any LLM-powered tool, this template eliminates guesswork and provides data-driven decision-making.
How It Works
1. User Input Trigger
The workflow starts when a user sends a message through a chat interface (like Telegram, Slack, or a webhook). This input is captured and duplicated for parallel processing.
2. Parallel LLM Processing
The prompt is sent to two separate AI Agent nodes configured with different models (e.g., GPT-4 vs Claude, or OpenAI vs OpenRouter). Each node maintains its own memory context, ensuring independent conversation history.
3. Response Logging to Google Sheets
Both model responses, along with the original user input and conversation context, are appended to a Google Sheets spreadsheet. This creates a permanent record for team review or automated scoring.
4. Side-by-Side Output Display
The workflow returns both responses to the chat interface, allowing the user to see them juxtaposed. This immediate visual comparison helps identify differences in tone, accuracy, or completeness.
5. Optional Automated Evaluation
Advanced users can add a third AI Agent node that reviews the logged responses and assigns scores based on custom criteria, creating a fully automated evaluation loop.
Who This Is For
This template is ideal for:
- AI Developers & Engineers building chatbots, agents, or LLM-integrated applications who need to select the optimal model.
- Product Teams launching AI features and wanting to validate model performance before rollout.
- Data Scientists conducting comparative analysis of different LLMs across various prompts.
- Business Stakeholders who need transparent, documented evidence for model selection decisions.
- Startups & SMBs balancing cost, accuracy, and speed when choosing an AI provider.
Pro tip: Use this workflow during your development phase to test 3–5 different models with a set of 50–100 real user prompts. The accumulated Google Sheets data will clearly show which model consistently delivers the best results for your application.
What You'll Need
- n8n instance (cloud or self-hosted) with access to AI Agent nodes.
- API credentials for at least two LLM providers (OpenAI, Anthropic, Google Vertex AI, OpenRouter, etc.).
- Google Sheets account and a prepared spreadsheet template (link provided in the workflow description).
- A chat interface trigger (Telegram, Slack, WhatsApp, or a simple webhook) to initiate the comparison.
- Basic understanding of n8n node configuration (setting system prompts, tools, and memory buffers).
Quick Setup Guide
- Copy the Google Sheets template: Use the provided link to create your own copy of the logging spreadsheet.
- Import the workflow JSON: Download the template and import it into your n8n workspace.
- Configure AI Agent nodes: Set your system prompts, tools, and choose your two comparison models.
- Connect Google Sheets: Authorize n8n to access your copied spreadsheet and map the output fields.
- Set up your trigger: Connect your chosen chat platform (Telegram, Slack, etc.) to the workflow trigger node.
- Test with real prompts: Send messages through your chat interface and watch the responses populate the sheet.
Key Benefits
Data-Driven Model Selection: Replace subjective hunches with logged, comparable outputs. Choose the LLM that actually performs best for your prompts.
Team Collaboration & Transparency: Google Sheets allows multiple stakeholders to review, comment, and score responses. Decisions become collaborative and documented.
Cost & Performance Optimization: Identify if a cheaper, faster model delivers comparable quality to a premium one—directly impacting your AI budget.
Scalable Testing Framework: Once configured, you can run hundreds of test prompts automatically, building a robust dataset for model evaluation.
Future-Proofing: Easily add new models to the comparison as they emerge. The workflow structure supports expansion beyond two LLMs.