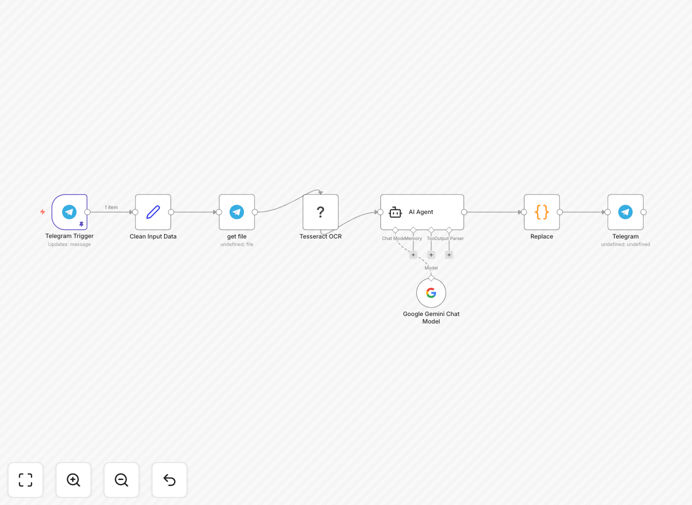
What This Workflow Does
This n8n workflow automates text extraction from images sent to a Telegram bot using Tesseract OCR technology. It solves the tedious manual process of transcribing text from photos, screenshots, or scanned documents by providing instant automated conversion.
Businesses and individuals can use this to quickly digitize receipts, business cards, invoices, or any printed text captured via mobile photos. The workflow handles the entire process - receiving the image via Telegram, processing it through OCR, and returning the extracted text to the user.
How It Works
1. Image Submission
Users send an image containing text to your Telegram bot. The bot immediately recognizes the image attachment and triggers the workflow.
2. OCR Processing
The workflow passes the image to Tesseract.js, an open-source OCR engine that analyzes the image, detects text regions, and converts them to machine-readable text.
3. Text Extraction
Tesseract processes the image and returns the extracted text in clean, editable format. The workflow can optionally clean up the output by removing artifacts or formatting the text.
4. Response Delivery
The workflow sends the extracted text back to the user via Telegram, completing the automated text extraction process in seconds.
Who This Is For
This workflow is ideal for:
- Business owners processing receipts or invoices
- Teams digitizing business cards or documents
- Researchers extracting text from book pages or screenshots
- Multilingual teams needing quick text translation
- Anyone regularly working with printed text that needs digitizing
What You'll Need
- An n8n instance (cloud or self-hosted)
- A Telegram bot token (create via @BotFather)
- Tesseract.js installed in your n8n environment
- Basic understanding of n8n workflows
Quick Setup Guide
- Download the JSON template file
- Import into your n8n instance
- Configure your Telegram bot credentials
- Test by sending an image to your bot
- Deploy the workflow for ongoing use
Pro tip: For best OCR results, ensure images are well-lit, in focus, and contain high-contrast text. Dark mode screenshots may require preprocessing for optimal recognition.
Key Benefits
Save hours on manual data entry by automatically extracting text from images with 90%+ accuracy for standard fonts.
Mobile-friendly workflow lets users capture text anywhere by simply snapping a photo and sending to your Telegram bot.
Scalable solution that can process hundreds of documents daily without additional staffing costs.
Multilingual support through Tesseract's extensive language packs for global business applications.