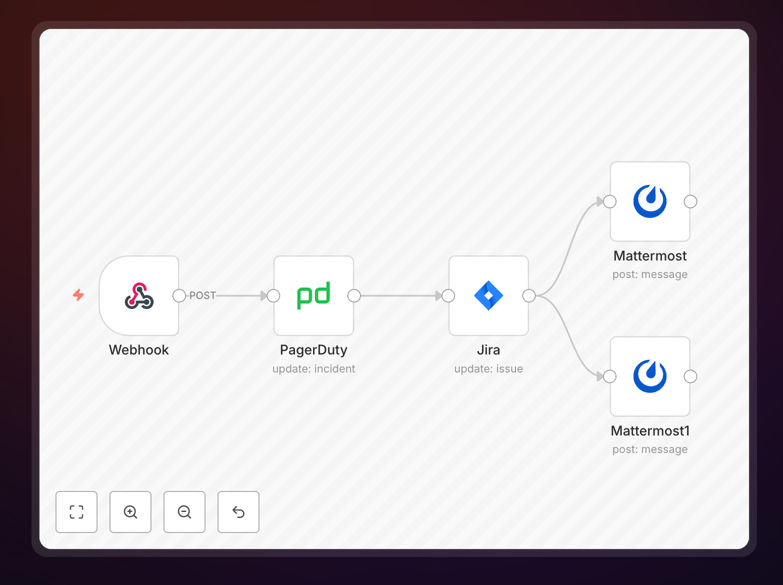
What This Workflow Does
When IT incidents occur, the manual process of updating multiple systems and notifying various teams creates delays and inconsistencies. This workflow automates the resolution phase of incident management, ensuring that when an incident is marked as resolved, all connected systems are updated simultaneously and stakeholders are notified immediately.
The automation listens for a "resolve" trigger, then performs three critical actions in parallel: changes the incident status to "Resolved" in PagerDuty, moves the corresponding issue to "Done" in Jira Software, and posts resolution notifications in both auxiliary and main incident channels in Mattermost. This eliminates the 15-30 minutes typically spent manually updating these systems after each incident resolution.
How It Works
1. Webhook Trigger
The workflow starts when a webhook receives the signal that the "Resolve" button has been clicked in your incident management interface. This could come from a dashboard, chatbot command, or automated monitoring system that has determined the issue is fixed.
2. PagerDuty Status Update
The workflow immediately updates the incident status in PagerDuty from "Acknowledged" to "Resolved." This ensures your on-call rotation is properly released and incident metrics are accurately recorded for SLA reporting and post-incident analysis.
3. Jira Ticket Transition
Simultaneously, the corresponding Jira issue is moved to "Done" status. All relevant incident details—timestamps, resolution notes, and assignee information—are preserved in Jira for future reference and compliance requirements.
4. Team Notifications
Two Mattermost notifications are sent: one to an auxiliary channel documenting that the incident has been marked as resolved in both PagerDuty and Jira, and another to the main incidents channel announcing that the on-call team has successfully resolved the issue.
Who This Is For
This workflow is ideal for IT operations teams, DevOps engineers, SRE (Site Reliability Engineering) teams, and technical support departments that manage incidents across multiple platforms. Companies with on-call rotations, SLA commitments, or compliance requirements for incident tracking will benefit most from this automation.
If your team spends significant time manually updating tickets after resolving issues, or if you've experienced communication gaps where some team members weren't notified of resolution, this workflow will streamline your entire post-incident process.
What You'll Need
- An n8n instance (cloud or self-hosted)
- PagerDuty account with API access
- Jira Software instance with appropriate project permissions
- Mattermost workspace with channel access
- A way to trigger the webhook (dashboard button, chatbot command, or monitoring system integration)
Quick Setup Guide
- Download the template using the button above
- Import the JSON file into your n8n instance
- Configure the Webhook node with your unique URL
- Connect the PagerDuty node with your API credentials
- Set up the Jira node with your project and issue details
- Configure both Mattermost nodes with your channel IDs and authentication
- Test the workflow by triggering the webhook with sample data
Pro tip: Use this workflow as part of a complete incident management system. Combine it with Part 1 (incident creation) and Part 2 (incident acknowledgment) for end-to-end automation from detection to resolution.
Key Benefits
Reduce resolution documentation time by 90%. What used to take 15-30 minutes of manual updates across multiple systems now happens instantly and consistently with zero human effort.
Ensure perfect synchronization between systems. No more "zombie incidents" that are resolved in one system but still show as active in another. All platforms reflect the same status simultaneously.
Improve team communication and transparency. Everyone—from engineers to managers—receives immediate notification when incidents are resolved, eliminating confusion and follow-up questions.
Create accurate incident metrics automatically. With consistent, automated status updates, your MTTR (Mean Time to Resolution) and other incident metrics become reliable for analysis and improvement.
Free up engineering time for actual problem-solving. Your IT team can focus on diagnosing and fixing issues rather than administrative ticket updates after each resolution.