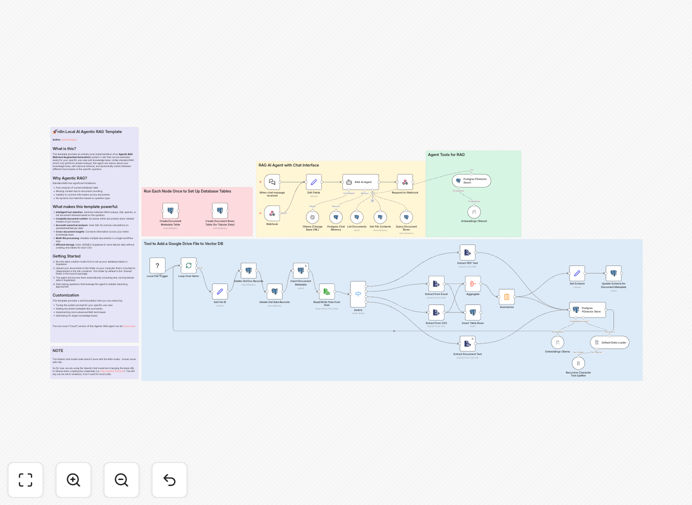
What This Workflow Does
This n8n workflow template implements a complete local document question answering system using cutting-edge AI technologies while maintaining full data privacy. It combines Ollama AI for local LLM processing, Agentic RAG (Retrieval Augmented Generation) architecture for context-aware responses, and PGVector for efficient semantic search across your documents.
The system allows you to upload documents (PDFs, Word files, text) and ask natural language questions about their content. Unlike cloud-based solutions, everything runs locally on your infrastructure, ensuring sensitive data never leaves your environment. This is particularly valuable for legal, healthcare, and financial organizations with strict data governance requirements.
How It Works
1. Document Ingestion
The workflow first processes uploaded documents by extracting text content and breaking it into semantically meaningful chunks. These chunks are then converted into vector embeddings using a local embedding model through Ollama.
2. Vector Storage
The generated embeddings are stored in PGVector, an open-source vector similarity search for PostgreSQL. This creates a searchable knowledge base where documents are represented numerically based on their semantic meaning.
3. Question Processing
When a user submits a question, the system converts it into an embedding using the same model. PGVector then performs a similarity search to find the most relevant document chunks based on semantic meaning rather than keyword matching.
4. Agentic RAG Response
The retrieved document chunks are fed to the local LLM (through Ollama) along with the original question. The Agentic RAG architecture enables the AI to reason about the context and generate accurate, well-supported answers while citing relevant source material.
Who This Is For
This solution is ideal for businesses that need to query internal documentation, research papers, or proprietary knowledge bases while maintaining complete data privacy. Common use cases include:
- Legal firms analyzing case files and precedents
- Healthcare organizations querying medical research
- Financial institutions analyzing reports and regulations
- Technical support teams searching knowledge bases
- Research teams working with sensitive data
Pro tip: For optimal performance, run this workflow on a machine with at least 16GB RAM and a modern CPU (or GPU if available). The hardware requirements will vary based on the size of your document collection and the Ollama model you choose.
What You'll Need
- n8n instance (self-hosted or cloud)
- Ollama installed locally with at least one LLM model downloaded
- PostgreSQL database with PGVector extension enabled
- Basic understanding of n8n workflows (or willingness to learn)
- Documents in supported formats (PDF, DOCX, TXT)
Quick Setup Guide
- Download the template JSON file
- Import into your n8n instance (Settings → Workflows → Import)
- Configure the PostgreSQL/PGVector connection details
- Set up Ollama connection parameters (host, port, model name)
- Test with sample documents and questions
- Deploy as an API endpoint or integrate with your existing systems
Key Benefits
Complete data privacy - Unlike cloud-based solutions, your documents and queries never leave your infrastructure, eliminating compliance risks.
Cost-effective AI - Running locally avoids per-query pricing models of commercial APIs, making it economical for high-volume usage.
Customizable knowledge - The system learns from your specific documents, providing more relevant answers than generic AI assistants.
Transparent sourcing - Answers include references to source document sections, enabling verification and deeper research.
Future-proof architecture - The modular design allows swapping components (LLMs, vector DBs) as better options emerge.