What This Workflow Does
This n8n workflow creates a complete monetization system for private large language models (LLMs), combining the x402 payment protocol with Ollama model hosting. It solves the challenge of commercializing specialized AI models without surrendering control to third-party platforms or exposing sensitive model weights.
The automation handles the entire transaction flow: verifying x402 payments, triggering Ollama model executions only for paid requests, and returning generated content to authorized users. This enables businesses to create paid API access for custom LLMs while maintaining full ownership of their AI assets.
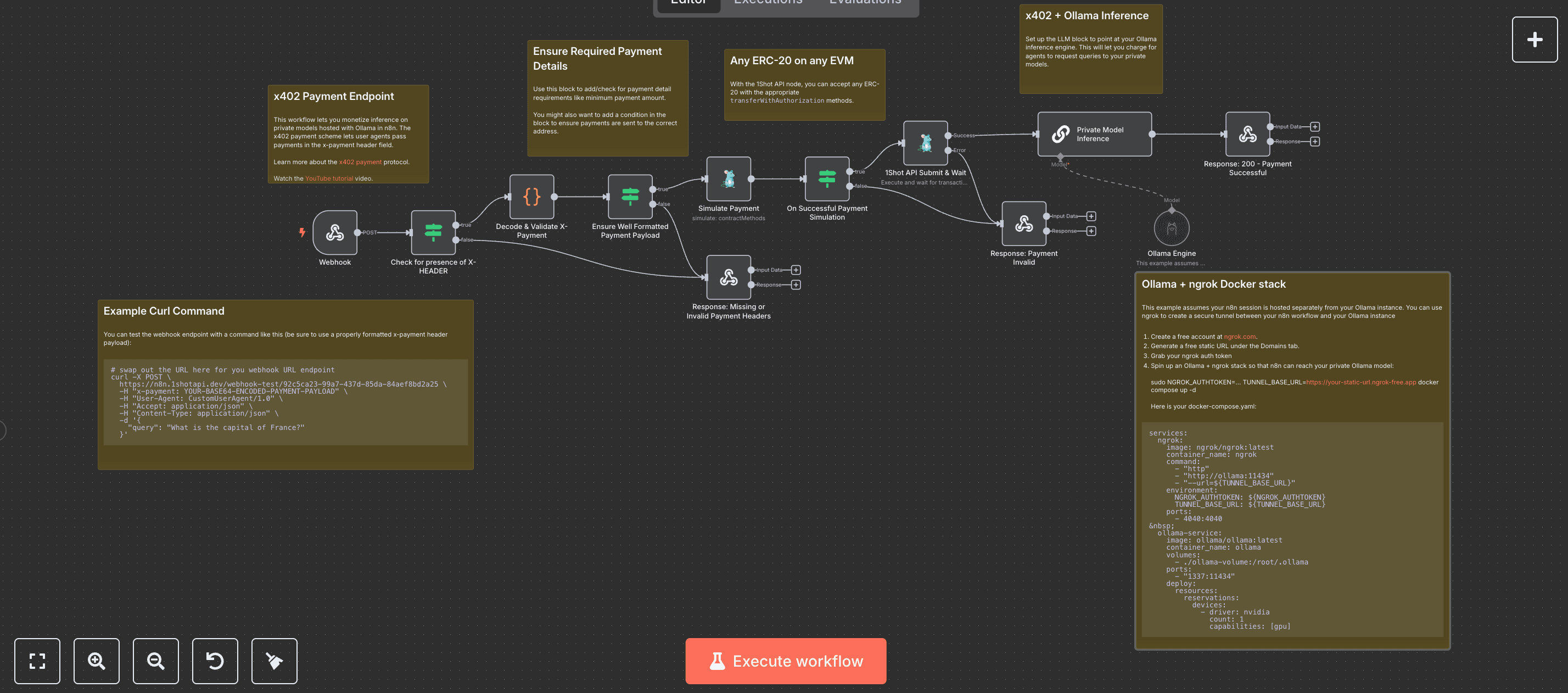
How It Works
1. Payment Verification
The workflow monitors x402 payment channels for incoming transactions matching your API pricing. Each payment includes metadata identifying the requesting user and query parameters.
2. Model Execution
Upon payment confirmation, n8n triggers the corresponding Ollama model with the user's prompt. The workflow handles all API communication between the payment system and model hosting environment.
3. Response Delivery
Generated content is returned exclusively to the paying user through encrypted channels. The workflow logs all transactions for reconciliation and usage analytics.
Pro tip: For high-volume applications, configure n8n to distribute queries across multiple Ollama instances based on model type or load balancing requirements.
Who This Is For
This solution benefits businesses that have invested in custom LLMs but lack a scalable monetization strategy. Ideal users include:
- AI startups with proprietary models
- Enterprises using internal LLMs for specialized domains
- Researchers commercializing fine-tuned models
- Developers creating niche AI services
What You'll Need
- Self-hosted n8n instance (version 1.0+)
- Ollama installed with your private models loaded
- x402 node configured for your payment channels
- Server infrastructure to host all components
Quick Setup Guide
- Import the JSON template into your n8n instance
- Configure x402 node with your payment channel details
- Connect Ollama node to your model hosting environment
- Set pricing parameters in the workflow settings
- Test with small payments before going live
Key Benefits
Revenue Control: Keep 100% of payments without platform fees. Set your own pricing models (per-token, per-query, or subscriptions).
Model Privacy: Commercialize models without exposing weights or training data through third-party APIs.
Flexible Deployment: Host models anywhere - from local servers to private cloud infrastructure.
Automated Scaling: The workflow handles payment processing and query routing as your user base grows.