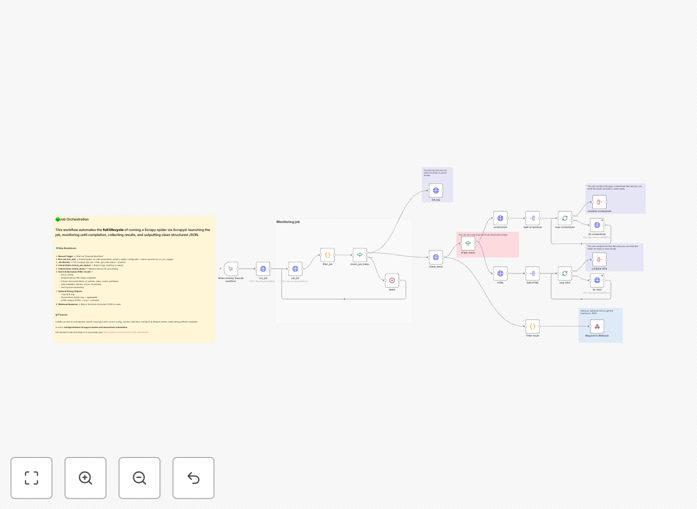
What This Workflow Does
This automation solves the challenge of manually collecting and processing web data by creating a complete pipeline from scraping to enriched deliverables. It coordinates Scrapyd spiders to extract data from target websites, then processes and enhances the raw results through n8n before delivering to your databases, spreadsheets, or business applications.
Typical implementations save 20-40 hours per week of manual data collection work while improving accuracy and consistency. The system handles scheduling, error recovery, and data transformation automatically, allowing teams to focus on analysis rather than data gathering.
How It Works
1. Spider Configuration
The workflow begins by deploying your configured Scrapy spiders to a Scrapyd server. Each spider includes specific selectors and parsing logic for its target websites, with built-in handling for pagination, JavaScript content, and authentication if needed.
2. Scheduled Execution
n8n triggers spider jobs according to your schedule (hourly, daily, or real-time). The system manages job queues and monitors progress, automatically retrying failed attempts with exponential backoff.
3. Data Processing
Raw scraped items pass through cleaning and validation steps. The workflow handles missing data, format standardization, and deduplication before enrichment begins.
4. Automated Enrichment
The system enhances scraped data by appending geographic coordinates to addresses, classifying content with AI, calculating derived metrics, or matching records against your databases.
5. Delivery
Final enriched data delivers to your chosen destinations - whether Google Sheets, Airtable, databases, or business applications through Zapier integrations.
Pro tip: Start with a small set of target sites to validate your selectors before scaling to hundreds of sources. Monitor for site structure changes monthly.
Who This Is For
This workflow benefits market researchers tracking competitors, e-commerce managers monitoring prices, recruiters aggregating job postings, and any business needing structured web data. Technical teams appreciate the scalable architecture, while business users benefit from ready-to-use enriched data without coding.
What You'll Need
- Scrapyd server (self-hosted or cloud)
- n8n instance (self-hosted or cloud)
- Zapier account for delivery integrations
- Target websites to scrape (ensure compliance with their terms)
Quick Setup Guide
- Download the JSON template
- Import into your n8n instance
- Configure your Scrapyd server details
- Add your spider configurations
- Set up destination apps in Zapier
- Test with a single spider before scaling
Key Benefits
Time savings: Automates what would take weeks of manual work into daily automated processes.
Data quality: Built-in validation and enrichment ensures higher quality than manual collection.
Scalability: Handles thousands of sources as easily as a handful with consistent performance.
Actionable insights: Enriched data arrives ready for analysis and decision-making.