What This Workflow Does
Many businesses use niche tools, custom-built systems, or services that don't have pre-built integrations in automation platforms. This creates data silos and manual work. This n8n template solves that problem by showing you how to connect to ANY web service using HTTP Request nodes.
The workflow demonstrates three practical use cases: pulling structured data from a REST API (mock albums), scraping content from websites (Wikipedia), and handling pagination for large datasets (GitHub stars). It transforms raw API responses into usable business data that can feed into your CRM, database, or reporting tools.
Instead of waiting for official integrations or writing custom code, you can immediately connect your unique tech stack. This template provides the foundation for unlimited integrations beyond what's available in standard connector libraries.
How It Works
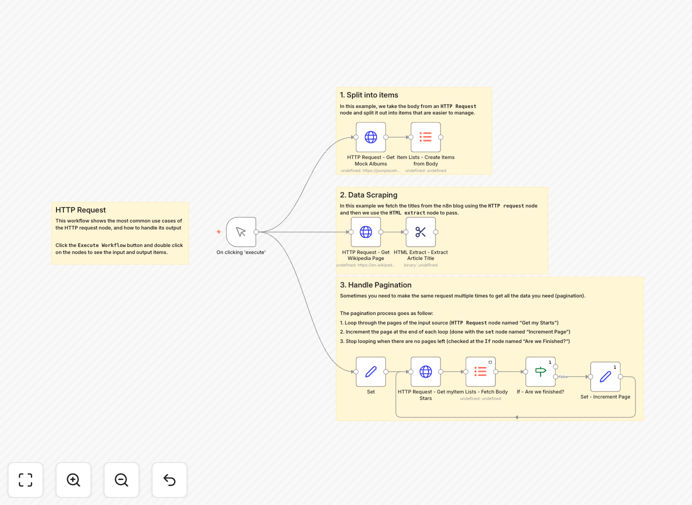
The workflow is divided into three parallel branches, each demonstrating a different HTTP integration pattern.
1. Basic API Data Retrieval
The first branch makes a simple GET request to a mock API endpoint (JSONPlaceholder albums). It receives JSON data, then uses the Item Lists node to split the response into individual records for processing. This pattern works for most REST APIs that return arrays of objects.
2. Web Scraping with HTML Extraction
The second branch fetches a random Wikipedia page using HTTP Request, then uses the HTML Extract node to parse the page title from the HTML. This shows how to work with non-API sources and extract specific data points from web pages for monitoring or content aggregation.
3. Pagination Handling for Complete Datasets
The third branch demonstrates professional API integration by handling pagination. It calls the GitHub API to list starred repositories, checks if more pages exist, increments the page counter, and loops until all data is retrieved. This ensures you get complete datasets even when APIs limit responses per request.
Who This Is For
This template is essential for businesses using specialized software that lacks standard integrations. Marketing agencies connecting client reporting tools, e-commerce stores syncing with custom inventory systems, SaaS companies pulling data from partner APIs, and IT teams automating internal tool connections.
Developers will appreciate the code-like control without writing actual code. Business users gain the ability to connect their unique stack without technical dependencies. Agencies can deliver custom integrations for clients faster than building from scratch.
Pro tip: Start with the pagination branch if you're pulling large datasets. Many APIs limit responses to 50-100 items per request, and missing pagination logic is the most common reason for incomplete data syncs.
What You'll Need
- A running n8n instance (cloud or self-hosted)
- API documentation for the service you want to connect to
- Authentication credentials (API keys, OAuth tokens, or username/password)
- The endpoint URL you want to call
- Basic understanding of HTTP methods (GET, POST) and response formats (JSON, XML)
Quick Setup Guide
Import this template into your n8n instance and follow these steps to adapt it for your needs:
- Replace the example URLs with your actual API endpoints in the HTTP Request nodes
- Configure authentication by adding API keys to request headers or using credential nodes
- Adjust response parsing based on your API's data structure (JSON, XML, or custom format)
- Test each branch separately before connecting them to your production systems
- Add error handling with additional IF nodes to manage API rate limits or temporary failures
Pro tip: Use n8n's "Execute Workflow" button to test each HTTP Request node individually. Check the response data structure before building downstream processing logic.
Key Benefits
Break free from integration limitations. Connect to any web service with an API, not just those with pre-built nodes. This future-proofs your automation as your tech stack evolves.
Reduce manual data work by 80%. Automate what would otherwise be copy-paste operations between systems. The pagination handling alone saves hours when syncing large datasets.
Maintain data consistency across systems. Automated API calls ensure timely and accurate data flow between your tools, eliminating version conflicts and stale information.
Scale integrations without coding. Add new API connections using the same patterns shown here. Once you understand HTTP Request nodes, you can integrate virtually anything.
Improve business agility. Respond quickly to new integration needs without waiting for developer resources or third-party connector updates.