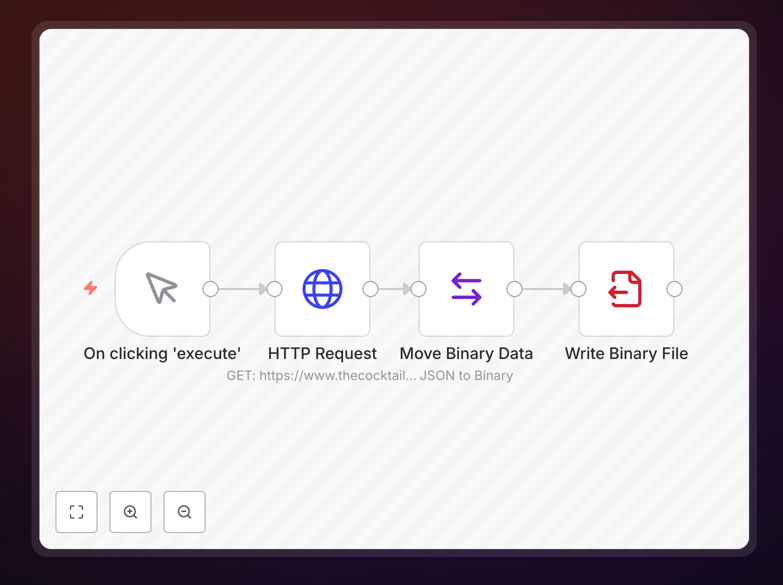
What This Workflow Does
This automation solution captures incoming data from the CocktailDB API via webhooks and stores it in structured JSON format. It solves the common problem of losing valuable API data by providing a reliable storage mechanism that preserves the original data structure while making it easily accessible for future processing.
The workflow acts as a middleware between the CocktailDB API and your storage system, handling authentication, data validation, and proper formatting automatically. This eliminates manual data handling while ensuring you maintain a complete record of all API interactions.
How It Works
1. Webhook Trigger
The workflow starts when the CocktailDB API sends data to your designated webhook URL. The trigger node captures the raw payload and initiates the automation.
2. Data Validation
Before processing, the workflow verifies the data structure matches expected patterns from the CocktailDB API, filtering out malformed requests or potential security threats.
3. JSON Transformation
The raw data is parsed and transformed into properly formatted JSON, with nested objects preserved and unnecessary metadata removed for cleaner storage.
4. Storage Execution
The final JSON payload gets saved to your chosen storage destination (database, cloud storage, or local file system) with proper timestamps and metadata for tracking.
Who This Is For
This template is ideal for:
- Developers integrating CocktailDB or similar APIs
- Businesses building drink recipe databases
- Data teams needing reliable API data storage
- Startups prototyping beverage-related apps
- Anyone needing historical API call records
What You'll Need
- An active CocktailDB API key
- n8n instance (cloud or self-hosted)
- Storage destination (database, S3, etc.)
- Webhook URL configured in CocktailDB
Quick Setup Guide
- Download and import the JSON template into your n8n instance
- Configure the webhook node with your public URL
- Connect your storage system (database, cloud storage, etc.)
- Test with sample CocktailDB API data
- Deploy and monitor initial data captures
Pro tip: For high-volume APIs, add a rate-limiting step to prevent storage overload during traffic spikes.
Key Benefits
Eliminates data loss by providing reliable storage for every API call, even during system outages or network issues.
Saves 10+ hours monthly by automating what would otherwise require manual data collection and formatting.
Enables better analytics through structured JSON storage that works seamlessly with visualization tools.
Reduces API costs by eliminating duplicate calls - stored data can be reused instead of fetching repeatedly.
Future-proofs integrations by maintaining complete historical records of API interactions.