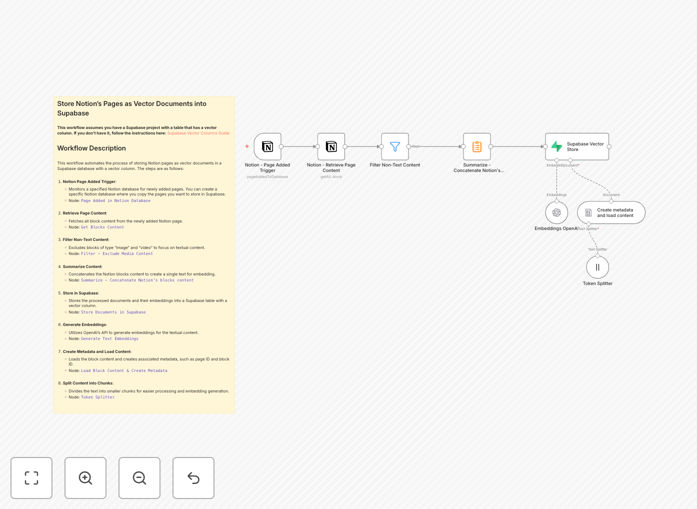
What This Workflow Does
This n8n workflow solves the challenge of making Notion content searchable at a semantic level. While Notion has basic search functionality, it can't understand the meaning behind your queries or find conceptually related content. This automation extracts text from Notion pages, processes it with OpenAI to generate vector embeddings, and stores these in Supabase with the original content.
The result is a powerful search system that understands what your content means, not just what words it contains. When integrated with a frontend, this enables features like "find documents similar to this one" or "show me all notes related to machine learning" - even if those exact terms don't appear in the documents.
How It Works
1. Notion Page Retrieval
The workflow starts by connecting to your Notion account and retrieving the specified pages. It handles authentication and pagination to ensure all content is captured, including nested blocks within pages.
2. Content Processing
Each page's content is extracted and cleaned, removing formatting while preserving the textual meaning. The workflow now includes a summarization step to consolidate content blocks into coherent documents before vectorization.
3. OpenAI Embedding Generation
The processed text is sent to OpenAI's embedding API, which converts it into a high-dimensional vector representation. These vectors capture semantic relationships between concepts in the text.
4. Supabase Storage
The original content, along with its vector embedding and metadata, is stored in a Supabase table configured with the pgvector extension. This enables efficient similarity searches later.
Who This Is For
This workflow is ideal for teams using Notion as their knowledge base who need better search capabilities. It's particularly valuable for:
- Engineering teams maintaining technical documentation
- Research groups collecting and analyzing information
- Product teams managing customer insights and feedback
- Any organization with growing Notion content that's becoming hard to navigate
What You'll Need
- An n8n instance (cloud or self-hosted)
- Notion integration with API access to your pages
- Supabase account with pgvector extension enabled
- OpenAI API key with access to the embeddings endpoint
- Basic familiarity with n8n workflow configuration
Quick Setup Guide
- Download the JSON template and import it into your n8n instance
- Configure the Notion node with your integration token and page IDs
- Set up the OpenAI node with your API key and preferred model
- Configure the Supabase connection with your project details
- Test with a single page before processing your entire knowledge base
Key Benefits
Transform Notion into a semantic search platform - Find content based on meaning rather than just keyword matching, dramatically improving discoverability.
Reduce time spent searching - Team members can find relevant information 3-5x faster compared to basic Notion search.
Future-proof your knowledge base - Vector embeddings enable advanced AI features like recommendation systems and smart content organization.
Centralize knowledge without migration - Keep using Notion as your authoring interface while gaining Supabase's search capabilities.
Scale with your content - The automated workflow handles growing documentation without additional manual effort.
Pro tip: Start with your most valuable or frequently accessed Notion pages first. Monitor search performance and refine your content structure based on what works best for semantic search.