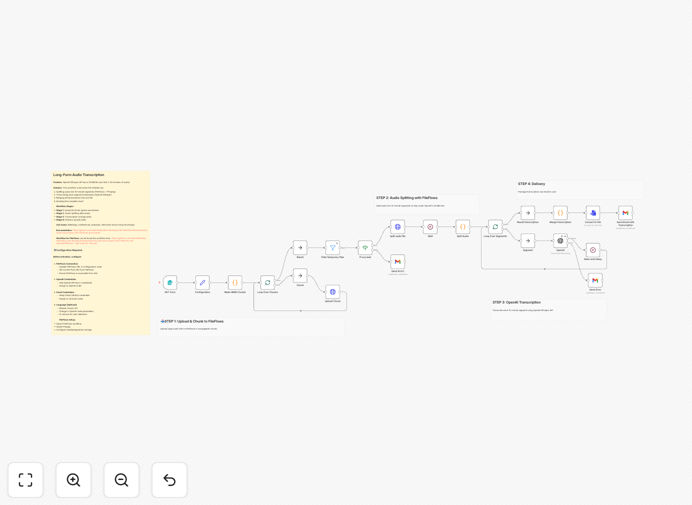
What This Workflow Does
This automation solves a critical limitation in audio transcription services - the 25MB file size limit imposed by most APIs including OpenAI Whisper. It enables businesses and creators to process lengthy recordings like podcasts, interviews, or lectures without manual splitting.
The workflow automatically segments large audio files, processes each segment through OpenAI's Whisper API, then combines the results into a single transcript. This eliminates hours of manual work while maintaining accuracy across the entire recording.
How It Works
1. File Upload and Preparation
Users upload MP3 files through a simple web interface. The workflow checks file size and prepares it for processing.
2. Automated Chunking
FileFlows splits the audio into 15-minute segments (under 25MB) using FFmpeg, ensuring optimal processing size for the Whisper API.
3. Parallel Transcription
Each audio segment is sent to OpenAI Whisper simultaneously, dramatically reducing total processing time.
4. Results Compilation
The workflow merges all transcript segments while maintaining proper timing and sequence, producing a unified document.
5. Delivery
The final transcript is emailed to the user in their preferred format (TXT, DOCX, or SRT for captions).
Who This Is For
This template is ideal for:
- Podcast producers needing show notes
- Academic researchers transcribing interviews
- Media companies processing long recordings
- Legal firms documenting proceedings
- Content creators making video captions
Pro tip: For best results, ensure your audio recordings are clear with minimal background noise. The workflow includes basic noise reduction, but source quality significantly impacts accuracy.
What You'll Need
- n8n instance (self-hosted or cloud)
- FileFlows with Docker and FFmpeg installed
- OpenAI API key with Whisper access
- Email service configured (Gmail recommended)
- Network connectivity between services
Quick Setup Guide
- Download and import the JSON template
- Configure FileFlows connection details
- Add your OpenAI API credentials
- Set up email delivery preferences
- Test with a sample audio file
Key Benefits
Save 80%+ time compared to manual transcription services or piecemeal processing.
Cost-effective at just $0.36 per hour of audio compared to $15-30 for human transcription.
Scalable processing handles batches of files automatically without supervision.
Consistent formatting across all transcripts regardless of file size.
Customizable output with options for raw text, formatted documents, or caption files.