What This Workflow Does
This automation template solves a critical business problem: accessing powerful AI capabilities without being locked into expensive, proprietary APIs. Many companies want to leverage language models for customer support, content generation, or data processing but hesitate due to cost, privacy concerns, or vendor dependency.
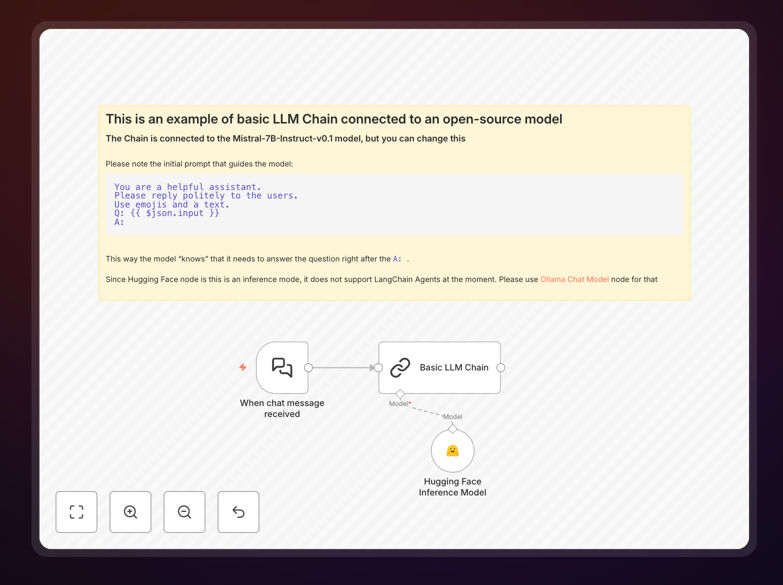
The workflow connects open-source models from HuggingFace's extensive library to your business processes using n8n. It demonstrates how to take a user message, process it through a language model chain with proper prompting, and return intelligent responses. You can adapt it for chatbots, document analysis, sentiment classification, or any text-based automation.
Unlike simple API calls, this template includes proper prompt engineering for smaller open-source models, which require more guidance than commercial counterparts. It's production-ready with error handling and can be extended with your business logic.
How It Works
1. Manual Trigger Initiation
The workflow starts when a new chat message or text input arrives. This trigger can be replaced with webhooks, scheduled runs, or other event sources in your actual implementation.
2. Prompt Preparation & Context Setting
The system structures the input with specific instructions tailored for open-source models. Unlike GPT-4 which understands vague requests, smaller models need clear role definitions and format expectations.
3. HuggingFace Model Inference
The prepared prompt is sent to a HuggingFace Inference endpoint. The template uses Mistral-7B-Instruct-v0.1 by default but can be configured for any of the 300,000+ models on HuggingFace.
4. Response Processing & Output
The AI response is cleaned, formatted, and passed to downstream nodes. You can connect it to databases, communication channels, or other business systems.
Who This Is For
This template is ideal for businesses that process sensitive data, have high-volume AI needs, or want cost-predictable automation. Specifically:
- Startups needing AI features without massive API bills
- Healthcare/legal companies that can't send patient/client data to third-party APIs
- E-commerce businesses automating customer support at scale
- Content agencies processing large volumes of text with consistent formatting
- Developers prototyping AI features before building custom solutions
Pro tip: Start with HuggingFace's Inference API for prototyping (pay-per-request), then migrate to self-hosted models on cloud GPUs when your volume justifies the infrastructure cost. This gives you the best of both worlds: flexibility and eventual cost control.
What You'll Need
- n8n instance (cloud or self-hosted version 1.19.4+)
- HuggingFace account with API access (free tier available)
- Basic understanding of your use case and desired outputs
- Optional: Additional nodes for your specific integrations (Slack, databases, etc.)
Quick Setup Guide
- Download the template using the button above
- Import into n8n via the workflow import function
- Configure HuggingFace node with your API token from huggingface.co/settings/tokens
- Test with sample input using the manual trigger
- Replace the trigger with your actual data source (webhook, schedule, etc.)
- Connect output nodes to your destination systems
- Deploy and monitor the workflow execution
Key Benefits
Cost predictability: Open-source models eliminate per-token pricing surprises. Once your infrastructure is set up, marginal costs approach zero for additional requests.
Data sovereignty: Keep sensitive customer data, proprietary information, and internal communications completely within your control. No third-party ever sees your data.
Customization freedom: Fine-tune models on your specific domain language, tone, and formats. Commercial APIs offer limited customization; open-source models can be tailored exactly to your needs.
Vendor independence: Avoid platform risk. If HuggingFace changes pricing or a commercial API shuts down, your automation continues working with your self-hosted models.
Scalability control: Scale vertically (better hardware) or horizontally (more instances) based on your exact needs rather than being constrained by API rate limits.